I enjoyed this a lot, but the other half of the equation, iOS remained elusive. I was surprised how much more difficult this turned out so I’ll document a bit of what I did in case it helps anyone else.
How to tell which 3rd party ad networks or trackers are in Apple iOS apps?
First, what is the most analogous file I could find to AndroidManifest? Turns out this is the Info.plist but the similarities with AndroidManifest don’t go far. In terms of 3rd party integrations, it does not seem like most make an appearance in the Info.plist so I guess I might need to dig further.
Next, my challenge was where to download files from. In the end, I decided to go ahead and try downloading from the iTunes store directly. The downside of this is that I will be using a personal iTunes account, though I don’t use Apple as a daily driver, it’s still a risk that they block/ban the account. I tried searching for whether this was possible, but didn’t find too much.
Downloading ipa files
After some trial and error with other tools, I found the open source ipatool which has a CLI interface. It requires authenticating with the email and password of your account, as well as some 2FA text messages to the related phone number.
The first issue I hit was that despite having entered an email, a phone number AND a credit card already for this account (#ApplePrivacy) I still needed to accept a license agreement via iTunes. Luckily, I was able to find this blog article for how to download IPA files for Windows by using an old version of iTunes (because of course Apple now blocks this in the newer versions). In the end I was able to get that older version of iTunes working on Linux with Wine and was able to accept the license agreement and download IPAs. This then made it so I could also use the CLI ipatool as well.
Now that CLI ipatool is working I am able to download IPA files and start doing more investigation
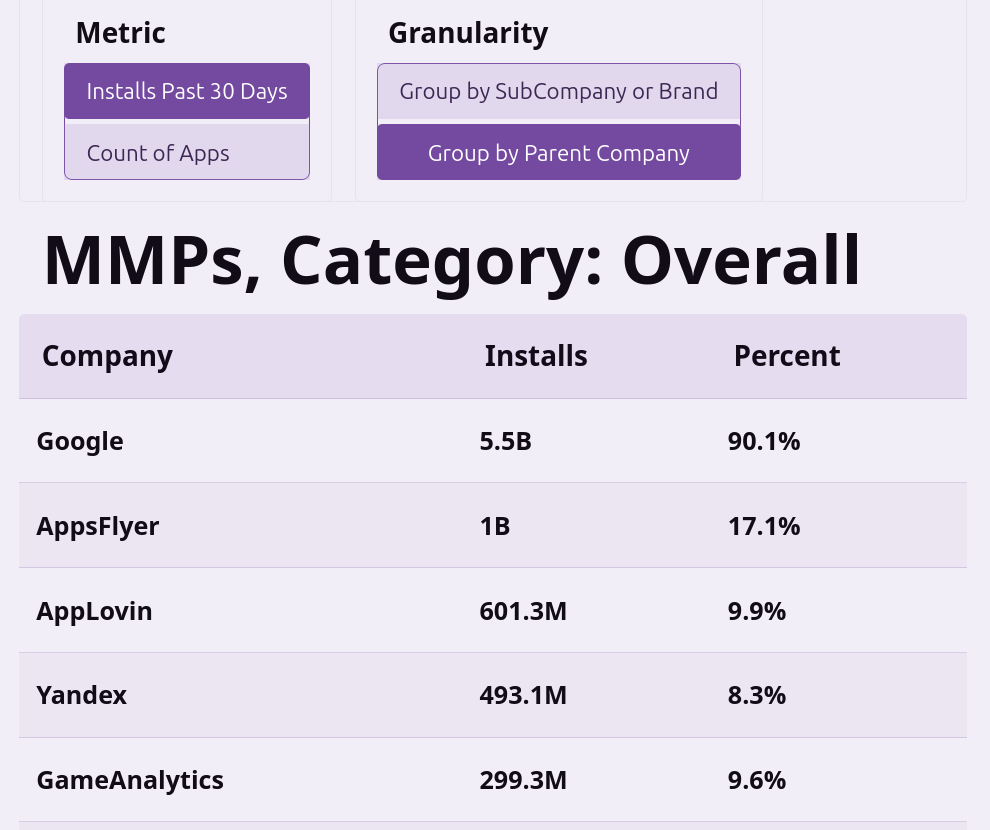
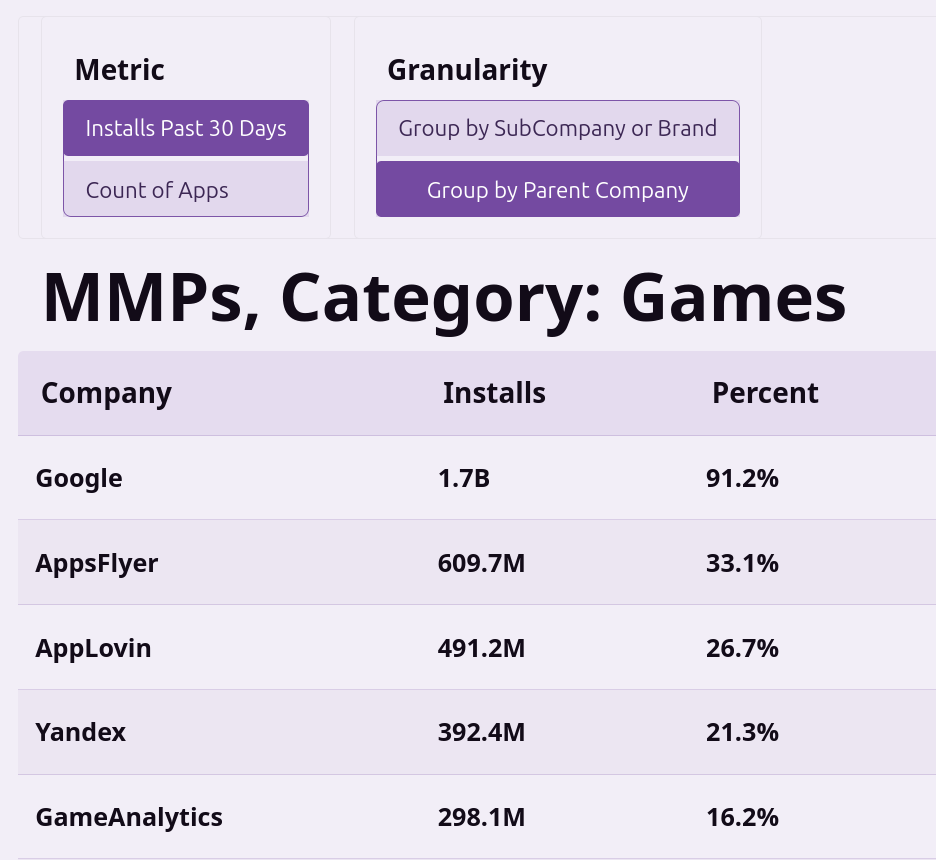
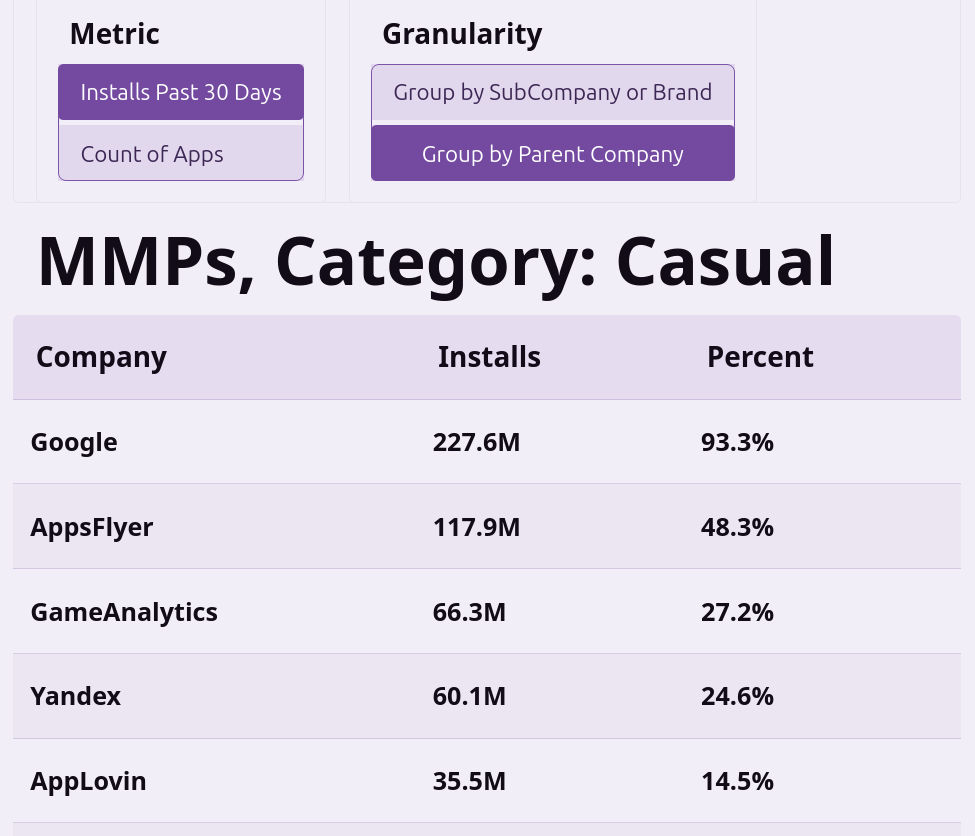
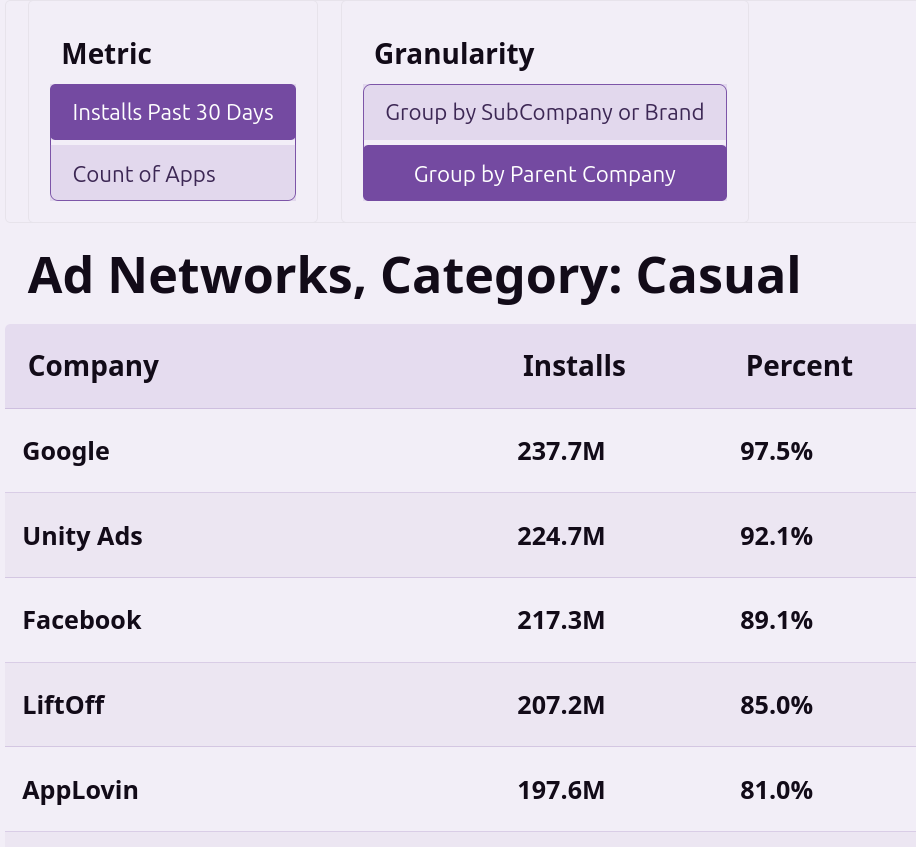
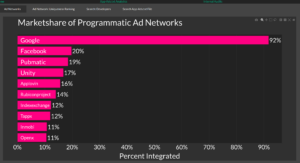
The data is pulled from the top ~10k Android apps, which I downloaded, de-compiled and examined their AndroidManifest.xml to determine which ad partners they might be using. The list of partners is something I manually created, so if there are any mobile MMPs or ad networks you think are missing, feel free to let me know and I’ll add them in.
My original thesis I wanted to learn about was what percentage of apps use AppsFlyer vs Adjust and the biggest surprise I got was that it was much lower than I expected and Firebase was much much higher than I expected.
Also, I’d love any feedback or questions that popup when people see this. I wouldn’t mind taking this a bit further.
I de-compiled TikTok (“com.zhiliaoapp.musically” v33.3.3 from Feb 2nd, 2024) from ApkPure.net and noticed that the way it called AppsFlyer looked a bit different than what I expected and quickly led me to a GitHub issue which makes it seem like they are using an outdated way to collect install information from Google Play which may have security vulnerabilities. Particularly, could a malicious app use this to ‘steal’ TikTok install attributions?
In this setup you see that TikTok is using a receiver com.appsflyer.SingleInstallBroadcastReceiver to listen for the com.android.vending.INSTALL_REFERRER event. This might allow a malicious app to listen for for the INSTALL_REFERRER event. You can see this is not recommended by AppsFlyer in this GitHub issue and is not their recommended installation setup.
I think the potential here might that if this version of TikTok is leaking the INSTALL_REFERRER data then
It could provide a malicious app valuable information in attempting to steal information about the source of TikTok’s users.
Additionally, a malicious app might be able to perform click jacking given that they know some information about the source of the install very early on.
And finally since the INSTALL_REFERRER is broadly scoped the malicious app could then send the a false INSTALL_REFERRER which TikTok may not be able to validate.
Would you like to see what data is coming out of TikTok when you first open it up? Let’s get to it.
Didn’t this used to be easy to do?
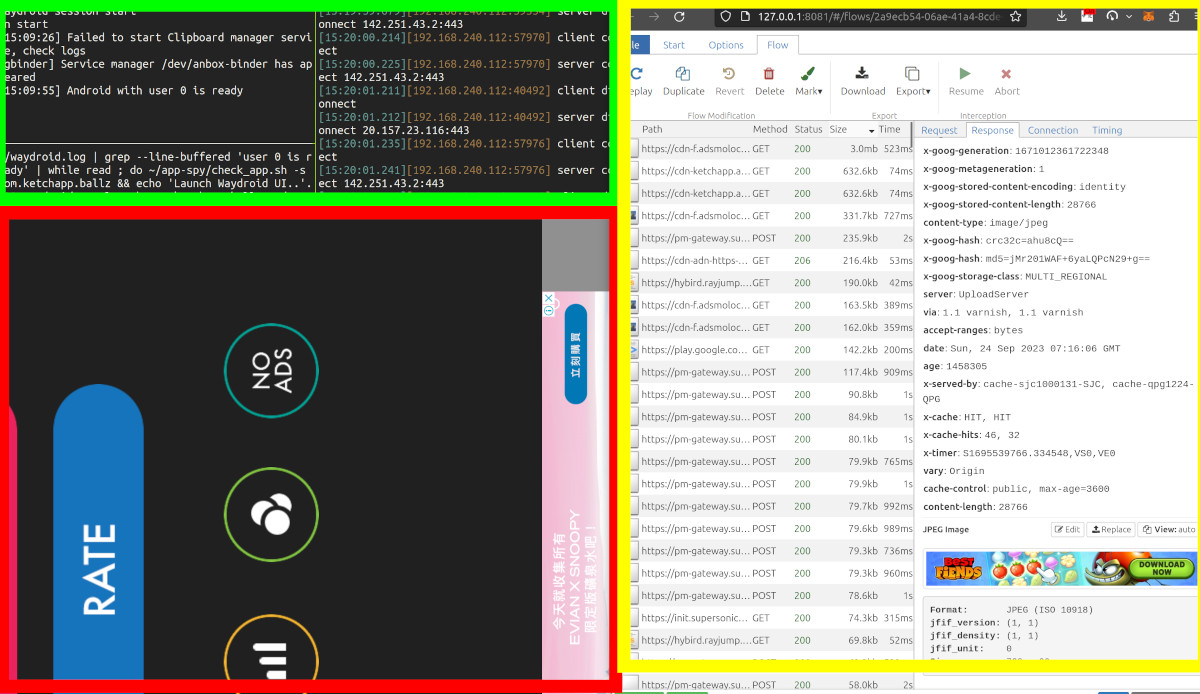
As security for iPhones and Androids increased it continually made viewing the traffic leaving your own device more difficult. This is in stark contrast to a regular web browser where you can easily open the network traffic for any site to see the back and forth of the network calls while you visit that site. For mobile apps, if you want to see the traffic on a computer, you need to do a proxy with a custom CA certificate. For years this was with Charles Proxy, Burpsuite and Wireshark. But apps continued to evolve and many began to put their own custom CA certificates inside the apps, meaning it was no longer enough to just forward the traffic to a proxy, you now had to unpin the SLL certificate within the app. This flow below is still possible with Charles or others, but in the end I ended up using the following tools.
Waydroid – Android Emulator: To install the target app
+ Magisk for root + allowing user certificates
+ LSPosed for SSL unpinning
MITM Proxy: to capture and view the decrypted traffic
I got the APK from APKpure.net and installed it into the emulator. We rolled the dice on a lucky day and happened to download TikTok v33.3.3 so you’ll be seeing that number a lot later. Then with the MITM proxy running, I opened the app for the first time.
Launching TikTok
All the request in the rest of the post are fired within 2-3 seconds of launching, so lots of back and forth within the app and on the network.
Keep in mind, this is all traffic from the emulator, so there are other network requests mixed in that are not from TikTok.
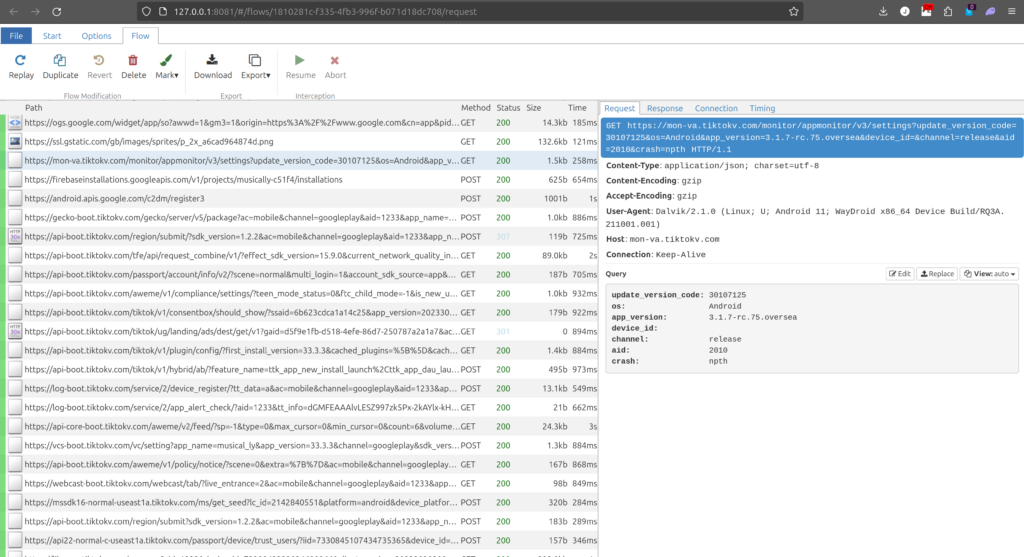
The first one that is for sure from TikTok. You you can see the request to tiktokv.com/monitor/appmonitor/v3/settings with some basic settings being recorded.
Here we see TikTok trying to figure out the carrier_region and network_sim_region all of which are empty due to Waydroid emulator not having a sim card.
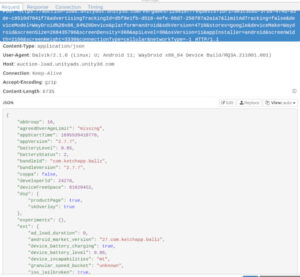
Now we see the main set of data coming out of the device. This information is repeated in most other requests back and forth. Let’s note some of the interesting ones:
op_region/sys_region: US
device_type: WayDroid x86_64 Device
device_brand: waydroid
language: en
os_api: 30
os_version: 11
openudid: 6b623cdca1a14c25
manifest_version_code: 2023303030
resolution: 3456*1970
dpi: 360
These are all accurate to the emulator Waydroid, running on my laptop, note the resolution. The op_region/local US and en are related to the Google Play account I am signed into with on the phone, while Asia/Taipei is the current timezone.
Next we see calls for api-boot.tiktokv.com/aweme/v1/compliance which note that I am not a teen or child. Additionally is_new_user=0 which must mean that I’ve before downloaded TikTok with this Google account. Keep in mind, this is all within a second or two of running the app, so I assume this must be coming from Android operating system, and it’s possible last year I had installed TikTok at some point on the emulator, though I don’t remember that.
GET https://api-boot.tiktokv.com/aweme/v1/compliance/settings/?teen_mode_status=0&ftc_child_mode=-1&is_new_user=0&ac=mobile&channel=googleplay&aid=1233&app_name=musical_ly&version_code=330303
Query
teen_mode_status: 0
ftc_child_mode: -1
is_new_user: 0
Bytes & Encoded data
Now we get to several sets of data that I am unsure how to decode. They generally were mixed in and looked like raw data as well as base64 looking encoded data inside JSONs. These were usually outgoing to log-boot.tiktokv.com/service/2/ . If anyone has some advice for how I can decode those, please let me know, I’d love to try. Below is one of the ones in a json called ‘tt_info’
Here’s another interesting one, maybe it’s reading into it too much, but it goes to passport/device/trust_users and the response trusted_users: null makes me think I’m not yet a trusted user 🤔
This one libra was super interesting, in the RESPONSE we see some interesting things. Looks like they are testing AppsFlyer as well as something related to mac address, though unclear what it is:
Later on in that we also see some lists of whitelisted js (javascript?) services that likely can run in the Webview. Interestingly, there is also a large list for music as well. I tried looking into these services and many seem like likely partners for tools like captcha, payment. faceueditor I couldn’t find though.
And now we’re getting to some content, like this still JPEG:
So, now it’s 3 seconds later, and let’s see where we are in the app experience:
{
"data": {
"/aweme/v1/compliance/settings/": {
"body": {
"about_privacy_policy_url": "https://www.tiktok.com/legal/privacy-policy-row",
"ad_personality_settings": {
"att_status": 255,
"is_follow_sys_config": false,
"is_np_user": 1,
"is_show_settings": false,
"limit_ad_tracking": false,
"mode": 0,
"need_pop_up": false,
"pa_revising_switch": false,
"pers_ad_data_received_partner_mode": 0,
"pers_ad_show_data_received_partner": false,
"pers_ad_show_third_party_networks": false,
"pers_ad_third_party_networks_mode": 0,
"unified_mode": 0
},
"age_gate_info": {
"age_gate_action": 0,
"age_gate_post_action": 0,
"register_age_gate_action": 0
},
"cmpl_enc": "UNKNOWN",
"commercial_content_library_url": "https://www.tiktok.com/adlibrary",
"device_limit_register_expired": true,
"extra": {
"fatal_item_ids": [],
"logid": "20240202034347AC84497362B5DDABA59B",
"now": 1706845428000
},
"idfa_popup_allow": false,
"interface_control_settings": "{\"rules\":null,\"use_new_control\":true,\"user_type\":\"-1\",\"version\":\"11\"}",
"log_pb": {
"impr_id": "20240202034347AC84497362B5DDABA59B"
},
"parental_guardian_name": "Family Pairing",
"policy_info_list": [
{
"policy_key": "privacy-policy",
"policy_url": "https://www.tiktok.com/legal/privacy-policy"
},
{
"policy_key": "terms-of-service",
"policy_url": "https://www.tiktok.com/legal/terms-of-service"
},
{
"policy_key": "tiktok-shoutouts-user-terms-of-service",
"policy_url": "https://www.tiktok.com/legal/tiktok-shoutouts-user-terms-of-service"
},
{
"policy_key": "cookie-policy",
"policy_url": "https://www.tiktok.com/legal/cookie-policy"
},
{
"policy_key": "virtual-items",
"policy_url": "https://www.tiktok.com/legal/virtual-items"
},
{
"policy_key": "rewards-policy-eea",
"policy_url": "https://www.tiktok.com/legal/rewards-policy-eea"
},
{
"policy_key": "privacy-policy-for-younger-users",
"policy_url": "https://www.tiktok.com/legal/privacy-policy-for-younger-users"
},
{
"policy_key": "copyright-policy",
"policy_url": "https://www.tiktok.com/legal/copyright-policy"
},
{
"policy_key": "changes-to-personalised-advertising-in-the-eea",
"policy_url": "https://www.tiktok.com/legal/changes-to-personalised-advertising-in-the-eea"
}
],
"policy_notice_enable": true,
"status_code": 0,
"terms_consent_for_register_info_new_users": {
"checkbox_agree_all_terms": "Agree to all",
"checkbox_privacy_policy": "Consent to the collection and use of personal information (Required)",
"checkbox_terms_of_use": "Consent to the Terms of Service (Required)",
"checkbox_tr_notification_subtitle": "Get notifications about trending videos and promotions on TikTok. You can review and edit your settings at any time. Not allowing this type of notification does not limit your use of the TikTok service.",
"checkbox_tr_notification_title": "Consent to the receipt of trending content and promotional notifications (Optional)",
"tiktok_privacy_policy_url": "https://www.tiktok.com/legal/terms-and-conditions-kr?lang=ko-KR",
"tiktok_terms_of_use_url": "https://www.tiktok.com/legal/page/row/terms-of-service/ko-KR",
"title": "Terms and conditions"
}
},
...
Let’s tap agree and see what happens.
POST https://api22-normal-c-useast1a.tiktokv.com/consent/api/record/create/v1?...
entity_keys: conditions-policy-device-consent
business_flow: consent_box
status: 1
And an updated set of compliance, similar to the one from above.
GET https://api22-normal-c-useast1a.tiktokv.com/aweme/v1/compliance/settings/?teen_mode_status=0&ftc_child_mode=-1&is_new_user=0
...
RESPONSE:
{
"about_privacy_policy_url": "https://www.tiktok.com/legal/privacy-policy-row",
"ad_personality_settings": {
"ad_free_subscription": {
"subscription_mode": 0
},
"att_status": 255,
"description": "With this setting, the ads you see on TikTok can be more tailored to your interests based on data that advertising partners share with us about your activity on their apps and websites.\nYou will always see ads on TikTok based on what you do on TikTok or other data described in our privacy policy.",
"disable_att_overwrite_pa": 1,
"enable_toggle_decoupling": true,
"is_follow_sys_config": false,
"is_new_user": 1,
"is_np_user": 0,
"is_show_3p_data_control": false,
"is_show_reset_entry": false,
"is_show_settings": true,
"is_teenager_mode": 0,
"limit_ad_tracking": false,
"mode": 1,
"need_pop_up": false,
"pa_revising_switch": false,
"pers_ad_data_received_partner_mode": 0,
"pers_ad_main_mode_title": "Using Off-TikTok activity for ad targeting",
"pers_ad_show_data_received_partner": false,
"pers_ad_show_interest_label": true,
"pers_ad_show_third_part_measurement": false,
"pers_ad_show_third_party_networks": false,
"pers_ad_third_party_networks_mode": 0,
"show_advertiser_settings": true,
"unified_mode": 0,
"use_new_interests": 1
},
"age_gate_info": {
"age_gate_action": 0,
"age_gate_post_action": 0,
"register_age_gate_action": 2
},
After Terms Of Service: And we’re off!
The app shows the video stream and the API requests are flying back and forth now, many a second, so there’s lots more to look at next time. Overall the data seems pretty standard with a few interesting things to look into like the still encrypted data, the connected services and of course, everything after you agree to those Terms of Service.
This led to a potential fix by using the very recent ClickHouse refreshable materialized views. These refreshable views work much closer to how materialized views work in other databases like PostgreSQL but come with additional benefits like setting the refreshes inside the materialized view logic itself.
Official Documentation: https://clickhouse.com/docs/en/sql-reference/statements/create/view#refreshable-materialized-view
At the time of writing, refreshable views are new enough that they require setting this to enable support. Since this is needed per session in which a table is created, you will need to use this setting. This shouldn’t be necessary after Q2 2024.
SET allow_experimental_refreshable_materialized_view = 1;
Then to make the view refreshable you just add REFRESH EVERY {INT} {TIME} like this:
CREATE MATERIALIZED VIEW attribute_impressions_mv
REFRESH EVERY 5 SECOND
TO attributed_impressions -- Specify the destination table
AS
WITH
merged_impression_event AS (
-- Ranked rows by impression time
SELECT
app.event_time AS app_event_time,
app.store_id AS store_id,
app.event_id,
...
What I then discovered though was that once a refreshable view is used, it will replace the entire contents of the destination table. This means that they likely will need further management in the future as the data grows. Additionally, they cannot be combined with the columnar data inserts I was using previously with AggregatingMergeTree.
So, once you add a refreshable view, all higher level aggregations will likely all have to be refreshable as well.
In the end, I was able to use refreshable views to solve my problem, but I am not certain they wont cause delays later due to the way they seem to refresh across all data. Perhaps I’ll have to find a way to narrow the range they aggregate.
The past few weeks I spent building a front-end for an app store crawler that I made. The end goal is just to provide an open front-end for the apps details for the approximate 2.5m apps (already 1/2 those are no longer live) I’ve crawled from the Google & Apple stores. The site is now live on appgoblin.info and hosts a variety of Android and iOS stats and store information. Hopefully it’s something that some marketers may find interesting, and the code is all free on Github.
History
Originally this came out of a curiosity I had about the IAB app-ads.txt standard in 2022. In order to scrape app-ads.txt files I had to first get all the iOS and Android apps + their respective publisher URLs. This ended with a small dashboard I put on https://ads.jamesoclaire.com/dash/ads but I never expanded it further.
While that project, like app-ads.txt itself, went unused, I remained interested in letting the database of apps keep growing.
Then in the fall of 2023 while on hiatus from real work, I started working on an API and UI. Creating the UI gave me exactly what I wanted, which was use cases for displaying the data. Adding one feature led to the next so now there are several sections to browse.
Features
App Details
Each app has it’s own page for all the data pulled from the app store as well as second order of information derived from that data such as installs per day or change in ratings over time.
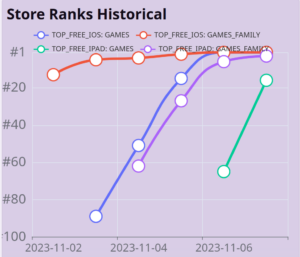
App Rankings
Since we have each apps history, it’s easy to build the historical ranking charts. In this example on the right, you can see a game quickly climbing multiple charts at once over the past month. This change in rankings is a great way to track an apps popularity over time.
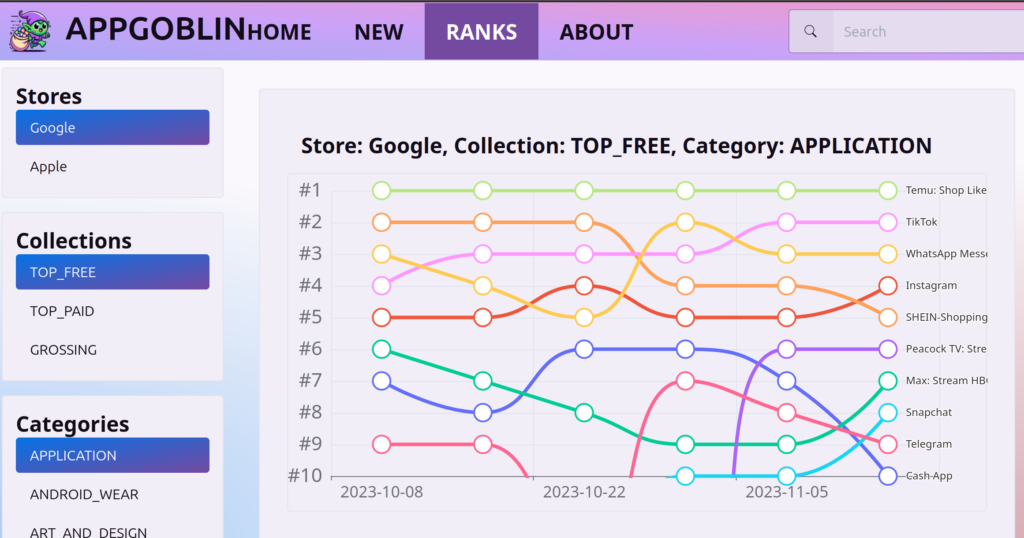
Ranking Charts
No site like this would be without it’s own app rankings page. This is straight from the Google & Apple stores top charts each day for tracking apps overtime.
New Apps
Now this might seem like an obvious one, but it really brought home the slow burn that the app stores barely surface new apps anymore. Long gone from both stores are any structured “new” sections which showcase new apps. The cynical answer here is that those sections actively take away from the ad-revenue generated by the in store advertising that makes up a large percentage of the apps on screen at any given time in each store.
So, why does AppGoblin exist?
Yes, there are a large number of similar offerings like data.ai and sensortower.com which have many more features. For me, I enjoyed learning more front-end and Javascript as well as give me something to do with the scraper which I had built previously (whats the point of a database if you cant use it somehow). For now App Goblin is simply here as a resource free of charge as it’s running costs only $20 a month or so in hosting.
Open Source Tech Stack
First is the underlying data which is collected and maintained from github.com/ddxv/adscrawler The adscrawler uses Python & PostgreSQL to crawl app stores to collect apps and their basic information like names and rating counts. This data is then stored to the PostgreSQL database. I also use some of the original parts of github.com/ddxv/app-ads-dash for monitoring the scraper. Hopefully in the future the parts specific to the scraper are moved to that repository.
The website itself is also open source and can be found at github.com/ddxv/app-store-dash The website is built from a Python backend API based on LiteStar which manages queries to the PostgreSQL database. The API is used by a JavaScript Svelte frontend with Tailwind and Skeleton for CSS. All projects are glued together with Systemd and web sockets where needed. Everything is hosted on AWS in the small EC2 instances.
As always, if you have any interest or questions please feel free to reach out.
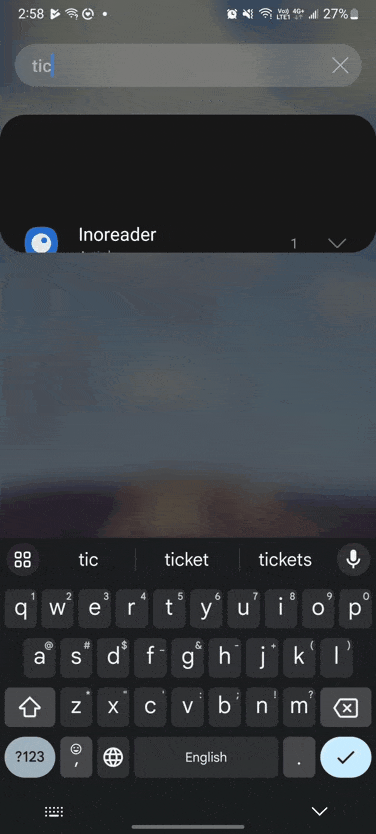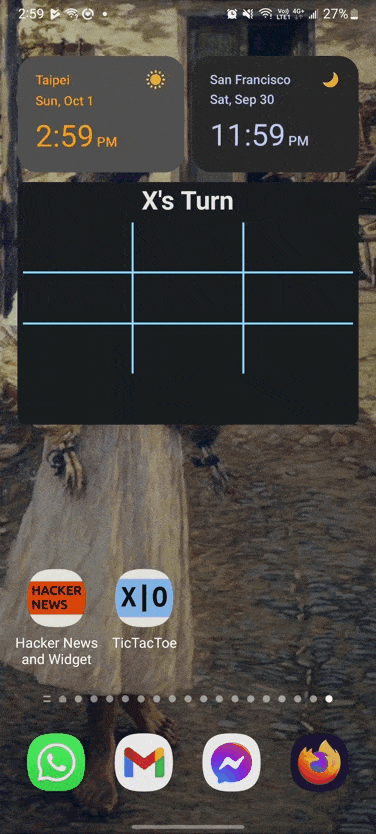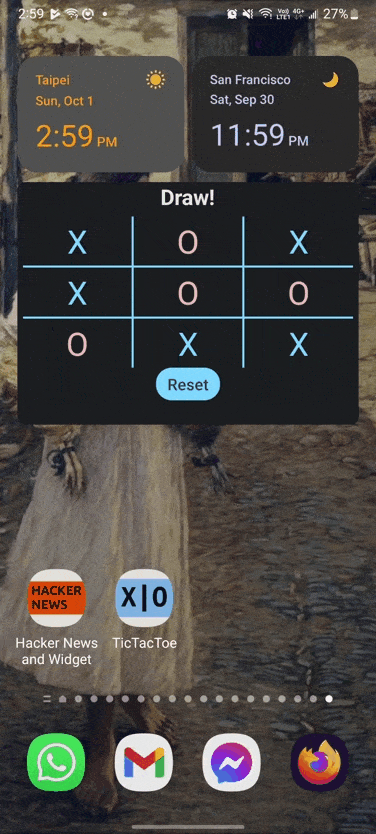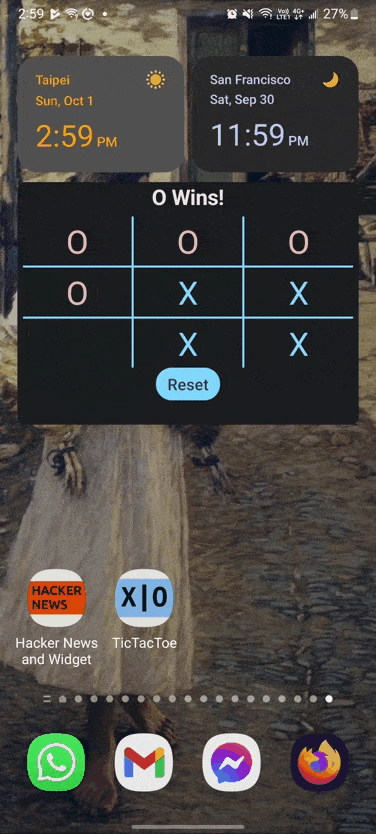
I love using widgets. I probably have too many of them on my phone’s home screen. News apps, weather apps, stocks, stats. I love being able to glance through them without opening the corresponding apps. This led me to realize though that I have seen very few widgets for mobile games. As I started working on making widgets, I realized you could actually make simple games inside of widgets.
Many apps use widgets already, but I think due to poor tooling, not many games have embraced widgets as a part of their game play loop. Recently I started looking into what some of the possibilities around making a simple game which could be played inside of a widget.
Widget Limitations:
Very limited dragging or other complex touches. This means no drag/swipe functionality. You can implement drag for lists, but picking up an item and dragging it around seems out of the question.
Animations are quite limited. I don’t think implementing most game animations would be possible.
Computations are subject to being cut off at any point. The widget must essentially be at rest at all times, this definitely limits what you can do, but still fits well for some gaming uses.
So, let’s try a Tic-Tac-Toe Widget
I chose Tic-Tac-Toe since it was the game I could think of with the least logic. My best guess was that implementing the game logic might be tricky or troublesome. Additionally, the turn based logic was perfect for falling into the background when the game is not being played.
This turned out to be pretty easy. I was able to get a prototype up and running within a day or so. One surprise I had was having trouble using a delay. In the end I gave up trying to implement a half second delay to simulate the computer ‘thinking’. I’m not sure if that is something that could be addressed later or not.
The game is mostly limited by the fact that it’s just tic-tac-toe that you’re playing, which gets old fast.
What about a more difficult puzzle game?
Next I went with a simple sliding puzzle game. The goal is to slide the pieces to slowly sort them into the correct order. These could be a puzzle image or as you see on the side just pure numbers. This would definitely be a bit flashier if I used images, and I think that is also doable for the future.
Though this is barely more complex than Tic-Tac-Toe the difficulties became apparent quickly. The biggest issue I faced was that the Android operating system will randomly shut down the widget’s thread which would cause the game to lose anything currently stored in memory.
This means that the game state can’t be stored in memory, but needs to be backed up to disk each time, then recovered. So each ‘turn’ is played by the user, then the game state is saved to disk, and when the widget is interacted with a second time, the game state is read back from disk first.
This means the game is quite solid and recovers from it’s process being ended without the player knowing, but it is just a bit laggy when ‘playing’ quickly as you can see in the gif.
That’s cool, but what about non puzzle games?
This is where I started getting more excited. While I think you could recreate many simple puzzle games as widgets, what is the point for the developer? While the player might enjoy some play outside the app any of the more pleasant animations or clever game play mechanics would remain out of reach for the game widget.
But what the widget does give the developer is a large real estate for the the player’s home screen. This could be a place for managing notifications to entice the player to open the game. A few examples:
Connection to in game functions like responding to events or setting a status
Notification that an in game timer is finished
Countdown to live events
Button to collect daily reward and open game to boost game re-engagement
Community Bulletin board
I think the ideas here are pretty basic, but could really help to reconnect games with their existing user bases.
If anyone out there has any interest in trying out the idea of building a widget for a game I’d be happy to help.
If you’re curious about either of the above examples you can get both on Google play and all code on GitHub:
Hacker News is one of my go to sites to read the best takes on the latest tech news.
Probably the reason I keep going back to it is the honest discussions and supportive community. But you probably already know this, since Hacker News is one of the most popular tech news sources out there.
And though there are dozens of high(er) quality Hacker News apps out there, I’ve always wished they supported widgets. In fact most apps I use I wish they supported Widgets.
I love waking up in the morning and checking the latest news from my home screen, rather than opening up web pages. This is why I decided to use Hacker News to make my first Android app and widget.
The whole experience was absolutely amazing compared to my recent attempt to use Unity. Android Studio + Kotlin and Jetpack Compose were an absolute dream to use. I rarely felt frustrated and was able to envision a few more interesting projects using widgets coming up next week.
In the meantime, please feel free to use my app or code:
It certainly isn’t anything amazing, but it was something that I really wanted to do for myself.
After recently stepping away from my position at Bubbleye and taking a month or two to enjoy some camping, family time and generally enjoying life I finally got back to Taipei and realized I had a unique opportunity to work on side projects that I’ve always wanted to do. Top of that list was to make a simple strategy game to better understand game design and the monetization side of games. To that end I built my own mini-RTS game using the game engine Unity.
Though Unity is the most popular choice for indie devs, I had an another motive: to learn more about Unity’s ads monetization side, especially as things change through the acquisitions of ironSource and TapJoy (originally acquired by ironSource).
How to make a good game? Be good at everything
I consider myself a generalist, competent at many things and flexible when learning new skills, but not necessarily skilled in all of the things it takes to make a game. There are so many integral parts for games like game graphics, game design, computer science and UI/UX, all of which need to be put together with good game design. It was a taxing job to work on build all these parts, and in the end also try to make a game design loop that was fun. I think this was something that surprised, because as I said I thought my strength would be that I can wear many hats, but making a game you REALLY need to do everything well, and missing even little parts of the loop made it glaringly obvious… the game wasn’t that good. As someone who enjoys the technical problems, it was easy to skip working on the game play loop itself, so I gained respect for game designers who do have the tenacity to tweak their game again and again to find out what would make a fun game.
So what did I accomplish? I learned a lot about Unity
Well, I learned quite a bit of how difficult Unity has become to use. Unity is bloated and was very painful to use. Many times, difficult problems would come down to conflicting settings within Unity itself. Warring Unity features which seem at odds with each other, and the only way to find out was to tap or untap another checkbox. The UI settings and features in Unity feel like a huge spaghetti of new features from last month and legacy support for systems from 10 years ago. I think what was frustrating is that unlike a true IDE, your code barely matters, and the Unity UI components often have little warning or information for what they might do.
This past month news broke that Unity’s pricing model was changing and the uproar was everywhere. This is fueled by a general distrust of Unity. I think it’s interesting, because if I look back, I certainly didn’t feel much trust in Unity’s product. Additionally, the code that is written, is so tightly bound to Unity it is impossible to move it to another Engine without simply rebuilding the entire game. Finally, I think that generally the state of mobile ecosystem is such that another middleman, no matter how respected, trying to assert it’s position to take a revenue share struck a nerve with many people.
Next
Having my first game in some ways did make me excited to make another. Parts were quite fun, but using Unity was a serious pain. I realized this when after the game I moved on and made a couple Android Apps in the weeks after using Android Studio. It was amazingly easy. The contrast of easily building apps in Android studio vs Unity’s spaghetti mess of code, buttons and packages that only maybe co-exist with each other was incredible.
Still, having my own apps is teaching me more about recent changes in the ad monetization landscape.
Also, having my own game gives me a good chance to work on more man in the middle attacks to watch mobile HTTPS traffic in and out of app and app SDKs. This is something I’m quite interested in, and being able to have a better understanding of how apps are built in 2023 is very useful.
These are my notes as I try to find a reliable way to collect HTTPS traffic from mobile apps on my phone or VM. Still have some questions as to which works best. This is all very much just a WIP / notes, but feel free to add or use. This took quite a bit of trial and error with a number of not working solutions, until I found this recent comment which worked perfect. Incase this helps anyone else I’m just writing my process here. Feel free to comment or let me know if you have other advice!
=====================
Waydroid VM & mitmproxy Setup Notes
Waydroid and mitmproxy are the two main tools you will use. Waydroid is an emulator for Android on Linux and will need a variety of custom software installed in it to make it work.
Ensure iptables is working. I was able to solve this by explicitly add /lib/x86_64-linux-gnu/xtables to /etc/ld.so.conf.d/x86_64-linux-gnu.conf and rebooting. This was reported working for Debian 11 and Ubuntu 20+
Setup iptables. I put the necessary iptable additions into a script as I ran them quite often, and can sometimes pause your local or Waydroid connection and needed to be cleared after using. You can use this script or copy paste the code block below and adapt as needed.
Run ./proxysetup.sh 8080 -w for waydroid. Use -l if mitm for other device
NOTE: proxysetup.sh runs sudo iptables -t nat -F at end to clear out iptables. This is because some of the iptable settings depending on proxy type can cause your connection to be blocked. But be warned, this will clear all custom iptables on your nat table you may have added.
proxysetup.sh runs the following commands, so feel free to run them yourself: ```#!/bin/bash sudo iptables -t nat -A PREROUTING -i waydroid0 -p tcp --dport 80 -j REDIRECT --to-port $port sudo iptables -t nat -A PREROUTING -i waydroid0 -p tcp --dport 443 -j REDIRECT --to-port $port sudo ip6tables -t nat -A PREROUTING -i waydroid0 -p tcp --dport 80 -j REDIRECT --to-port $port sudo ip6tables -t nat -A PREROUTING -i waydroid0 -p tcp --dport 443 -j REDIRECT --to-port $port sudo sysctl -w net.ipv4.ip_forward=1 sudo sysctl -w net.ipv6.conf.all.forwarding=1 sudo sysctl -w net.ipv4.conf.all.send_redirects=0 mitmweb --mode transparent --showhost --set block_global=false ```
Start Waydroid service: waydroid session start
Start Waydroid UI: waydroid show-full-ui and check internet
Inside Waydroid, if internet can’t connect try sudo waydroid shell and check ip link and ip addr to see if firewall blocking. More info at: ArchWiki Waydroid Networking
LSPosed Zygisk module trying to provide an ART hooking framework which delivers consistent APIs with the OG Xposed, leveraging LSPlant hooking framework. We will use this to install SSLUnpinning in a future step.
Finally, we can install our two custom tools into Magisk & LSPosed respectively:
MagiskTrustUserCerts This Magisk module will take your user CA certs and move them to system or ‘root’ CA certifications which more apps will trust.
SSLUnpinning This LSPosed module helps to unpin apps during runtime.
Once everything is installed, shut down and open Waydroid and mitmproxy one more time. After this you should be able to see clear text HTTPS requests from your Waydroid VM.
========
Other Tools
Emulator vs Phone
This is the first question and probably the most dependent on what you want to achieve. Working on a real device gives more space between your device and the proxy which makes things easier. The extra space is costly in other ways. For example, I would prefer to have a single instance running on the computer to collect information, but using a phone is easier but has the physical requirement of a device connected to the network.
Phone
Physical separation allows for clearer testing. Fully functional device means your input and output work as expected.
Emulator – Waydroid
Emulator running on the same computer causes more complicated networking to ensure you don’t block your own traffic. Troubleshooting is trickier as it’s more difficult to easily access parts of the emulator that a phone is easy to access. For example, I spent much more time than I would have expected to move a VPN configuration file from my computer to the virtual machine emulator than I would have ever expected. Adding the same configuration to the phone was a simple QR code scan.
Emulator running in a virtual machine allows for a future use case of running the whole thing in the cloud without a physical device.
Proxies
As far as I know, the only way to capture the HTTPS traffic is to use a proxy. This is in the form of an application running on a separate (virtual or physical as mentioned above) device. The hardest part here is the Certificate Authority which signs the HTTPS traffic when it leaves the app. More sophisticated apps, to prevent fraud, do a variety of actions to prevent the user or 3rd parties from capturing the data in each HTTPS request.
I tried this first as it comes with Python library which would make capturing data for later analysis much easier. Mitmproxy has a few different modes, and ultimately I found that mitmproxy --mode wireguard which runs via VPN captured a good amount of traffic, but still had target SDK traffic unable to be opened. Mitmproxy has a built in tool to help installing the certificate in Android as a user certificate. This will capture some HTTPs traffic, but for some apps and many SDKs this does not capture their traffic. Traffic can be captured in several ways: CLI tool for analysis of live traffic in memory, CLI dump to file and in memory live in browser of choice.
I first used Charles nearly 10 years ago, and it doesn’t feel like it’s changed much, but is actively maintained. When I first started using Charles it was a breeze to use, CA was less of a problem. But as Android changed it also now has the problems of CA needing to be installed, and helps the user by providing it’s own signed certificate which can be installed as a user certificate. Charles is a standalone program that you run and as such it does have a fair amount of issues on my linux environment related to it’s display sizes.
Community edition that is free to use. Runs in browser and comes with it’s own CA tool.
Android Certificate Authority
These are the certificates used to sign HTTPS traffic to keep it secure. In Android there are three levels: User, System (root) and App Pinned Certificates. In Android settings you can add a CA which will be considered “user”. Apps can choose whether to ignore this certificate. System CAs can only be set by a root user. While a user can install user CA’s, apps do not have to use these. CAs can be set by users as root certificates. I believe this must be set regardless of device or VM. The majority of the certificates provided by the proxies don’t seem to open a lot of HTTPS traffic. This is likely because Android N (API level 24) certificate pinning was introduced in 2016 and at this point most SDKs and Apps use this for transferring traffic.
This is installed on a device or emulator. An Xposed addon that can be installed to force apps to use root authorities and prevent them from pinning their own CA.
This can be installed in a separate linux environment and is used to modify an app’s apk before being installed into a VM emultator or phone. It attempts to get around the app’s certificate pinning by patching the APK to disable certificate pinning.